
1. はじめに
最近、生成AIの分野で「Qwen-Image」というモデルが大きな注目を集めています。
Stable Diffusion など既存の画像生成AIを使ったことがある方は多いと思いますが、Qwen-Image にはそれらとは異なる大きな特徴があります。
-
テキスト理解力が高い
特に文字生成に強く、日本語を含めた多言語で指示したとおりの画像を出しやすい。 -
自然な構図やレイアウトに強い
単純な被写体だけでなく、複雑なシーンや背景の理解も比較的得意。 -
オープンソースで公開されており、ローカルで利用可能
GPUを持っていれば、インターネットに依存せず自分のPCで動かせる。
こうした理由から、今クリエイターやAIユーザーの間で「Qwen-Imageを試してみたい!」という声が急増しています。
しかし、導入方法やファイルの選び方がやや複雑で、初めて触れる方にはハードルが高い部分もあります。
この記事では、初心者でも迷わず導入できるように、必要な環境からワークフローの選び方、実際の使い方まで徹底解説します。
2. Qwen-Imageとは?概要と特徴
Qwen-Image は、中国Alibabaが開発している「Qwen」シリーズの一部で、テキストから画像を生成する大規模AIモデルです。
すでに言語モデル「Qwen-LLM」やマルチモーダルの「Qwen-VL」なども公開されていますが、その中で 画像生成専用に特化したモデル が Qwen-Image です。
特に注目されているのが以下の点です。
ポイント
-
多言語対応:英語だけでなく、日本語、中国語など幅広い言語を理解できる
-
文字生成に強い:看板やポスターなど、文字を含んだ画像も自然に描ける
-
高精細:最新の学習技術で、細部の描写やリアル感も高い
Stable Diffusion が「汎用的にLoRAやカスタムで拡張できる強み」を持つのに対し、Qwen-Image は「テキスト理解力」と「自然な文字生成」に特化しているのが大きな違いです。
3. 導入に必要な環境
Qwen-Image はローカルPCで動かせますが、必要な環境を把握しておかないと途中でエラーが出やすいです。
ハードウェア
-
GPU:NVIDIA製が必須(CUDA対応)。
-
VRAM 8GBクラスでも蒸留版なら動作報告あり
-
より安定して利用するには 12GB以上、オリジナル版を使うなら 16GB以上推奨
-
-
メモリ:16GB以上推奨。
-
ストレージ:数GB〜十数GBの空き容量。
ソフトウェア
-
ComfyUI(最新版):Qwen-Imageを動かすフロントエンド。
-
Python 3.10+(ComfyUIが要求するバージョン)。
-
CUDA / cuDNN:GPUで高速に処理するために必要。
もしGPUのVRAMが少ない場合は後述する「蒸留版」を選ぶことで、より軽く動かすことができます。
4. ワークフローの入手と選び方
Qwen-ImageをComfyUIで動かすには「ワークフロー」と呼ばれる設定ファイルを導入します。
これをダウンロードするページとして、多くのユーザーが参考にしているのが ComfyUI WikiのQwen-Image解説ページ です。
ここでは 2種類のワークフロー が配布されています。
① 公式版(オリジナル版
-
高精細で忠実な生成が可能
-
推奨環境:VRAM 16GB以上
-
画質重視、性能に余裕があるPC向け
② 蒸留版(軽量版)
-
高速・軽量でPC負荷が少なめ
-
動作報告:VRAM 8GBクラスでも利用可能
-
推奨環境:12GB以上あればより安定
-
低スペック環境や入門用におすすめ
選び方の目安
| PCスペック | 推奨ワークフロー |
|---|---|
| VRAM 16GB以上 | 公式版(オリジナル) |
| VRAM 12GB前後 | 蒸留版(軽量版)が安定 |
| VRAM 8GB | 蒸留版(動作報告あり。出力サイズや設定を調整推奨) |
初心者で「どっちにするか迷う…」という場合は、まず 蒸留版(軽量版) を選んでおくのが安心です。
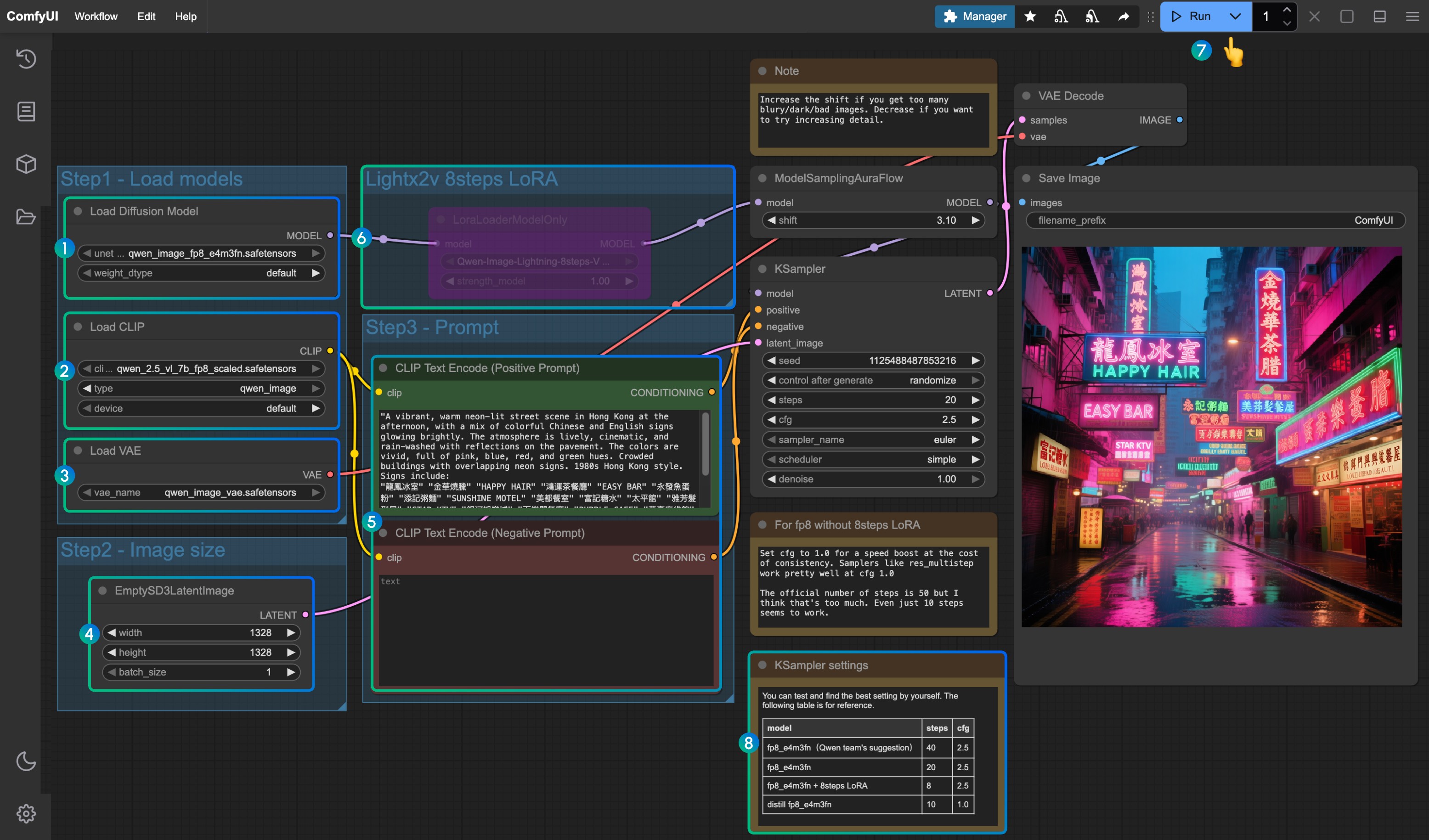
5. 導入手順
(1) ComfyUIのアップデート
すでにComfyUIを導入済みの場合でも、最新版に更新しておくことをおすすめします。
ポイント
-
Gitで導入している場合 →
git pullで更新可能 -
ComfyUI Managerを利用している場合 → 「Update」ボタンから簡単に更新可能
-
Zip版で導入している場合 → 最新版を公式リポジトリから再ダウンロード
更新方法は人によって異なるため、ご自身の導入スタイルに合わせて実行してください。
(2) ワークフローの配置
ダウンロードしたワークフローは JSONファイル 形式になっています。特別なフォルダは必須ではないので、まずは任意の場所(例:デスクトップやダウンロードフォルダ)に保存してください。
ComfyUI を起動し、画面右上の 「Load」ボタン からその JSON ファイルを選択すれば、すぐにワークフローを読み込むことができます。
もし複数のワークフローを管理したい場合は、ComfyUI/custom/workflows フォルダを作成し、その中にまとめて保存しておくと整理しやすいです。これは必須ではありませんが、後から複数のプロジェクトを切り替える際に便利です。
(3) モデル関連ファイルの配置
Qwen-Imageを動かすために以下のファイルをダウンロードして指定の場所に置きます。
ポイント
-
モデル本体(ckptやsafetensors形式)
-
VAE(画像圧縮展開用)
-
テキストエンコーダー(指示文を数値化)
配置場所はワークフロー内のノード設定に従って指定しましょう。
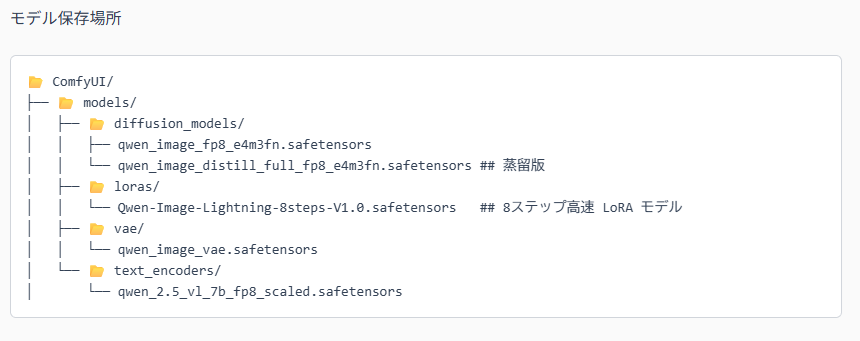
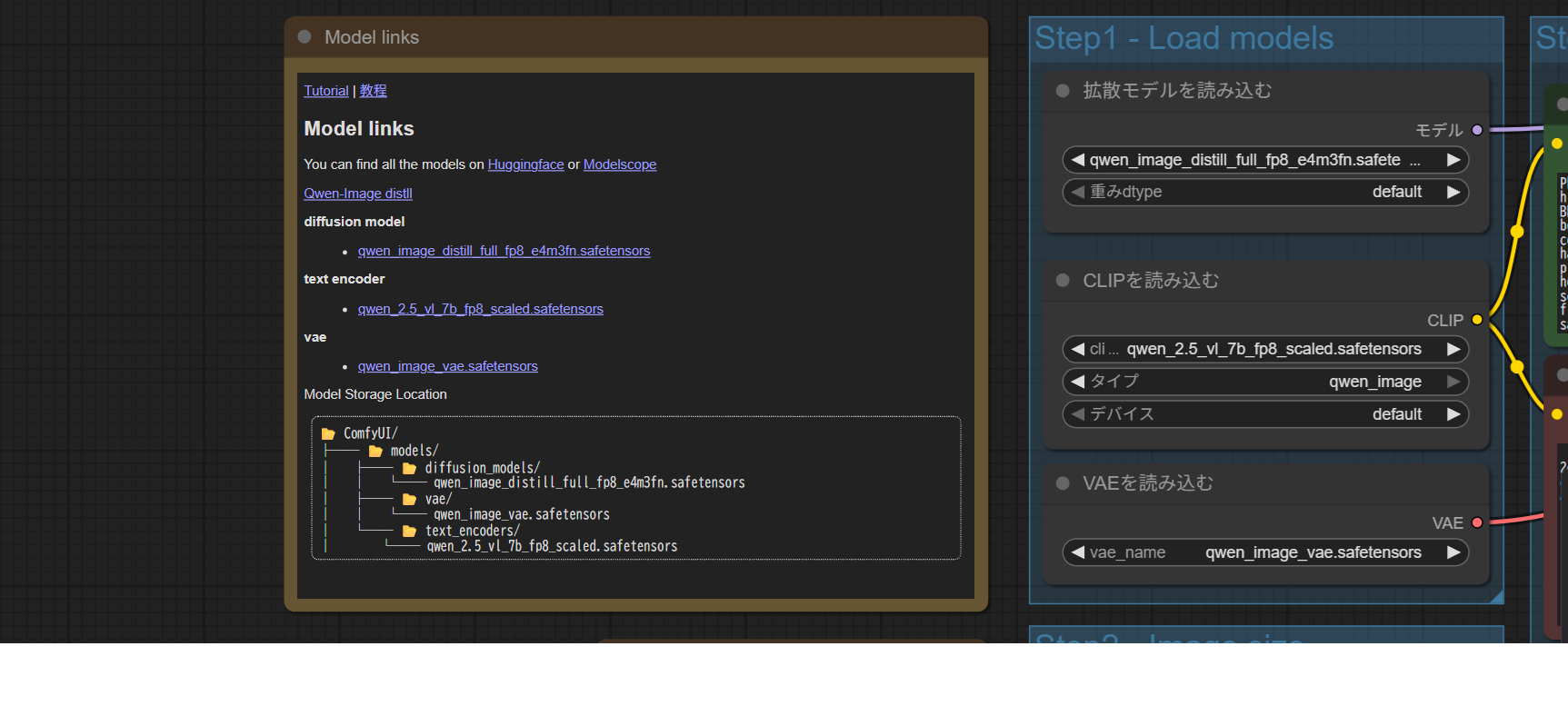
ワークフロー内にもダウンロードするファイルやそれらの格納場所を示したメモがあります
6. 実際に動かしてみよう
導入が完了したら、実際に動かしてみましょう。
生成例(AI美女)
(1)顔系のプロンプトを固定して、衣装・ポーズ・背景を色々と変えてみました。顔はある程度固定できそうです。

(2)文字をひらがな、カタカナ、漢字にしてテストしてみました。類似の文字があるとひらがなは難しいかもしれません。また漢字は画数次第ではうまくいきそうな感じです。

7. まとめと今後の展望
この記事では、Qwen-ImageをローカルPCで導入する流れを解説しました。
ポイント
-
Qwen-Imageは文字生成に強く、多言語対応が魅力
-
ワークフローは「公式版」と「蒸留版」の2種類
-
高性能PC → 公式版
-
ミドル/低スペックPC → 蒸留版(8GBでも動作報告あり。ただし12GB以上推奨)
-
-
実際に動かすには ComfyUI最新版とモデルファイルの導入が必要
特に蒸留版のおかげで、これまで「VRAMが足りなくて諦めていた」というユーザーでも比較的スムーズに試せるようになっています。
今後はLoRAや追加モデルが公開され、さらに自由度の高い活用が期待できます。
ぜひこの記事を参考に、ご自身の環境で Qwen-Image を動かしてみてください!
-

-
参考【超簡単】ComfyUIでPony Diffusionを動かす!モデルとワークフローの導入方法
続きを見る
 えなこ写真集『エピローグ』デジタルエディション
えなこ写真集『エピローグ』デジタルエディション
3,300円
{kind=link}